
LogDNA is now Mezmo but the product you know and love is here to stay.

An organization’s logging platform is a critical infrastructure component. Its purpose is to provide comprehensive and relevant information about the system, to specific parties, while it's running or when it's being built. For example, developers would require detailed and accurate logs when building and implementing services locally or in remote environments so that they can test new features. On the other hand, QAs and staging environments would find it extremely noisy to maintain all those accumulated logs; they would require more refined logging information that mimics the production stream of events.
In this tutorial, we’ll provide a series of necessary steps to deploy LogDNA agents for QA and staging environments. We will also explain the must-use features and supporting services that allow those teams to discover potential problems early.
Setting Up A Staging Environment
The first thing you need to do is sign up with LogDNA. When this process is finished, you can explore their dashboard page:

On the dashboard page, you have the option to pre-load sample log data, or configure an agent collector yourself (or you can do both). If you select the sample data, you can add applications later. Here is what the screen looks like when the sample data is loaded:
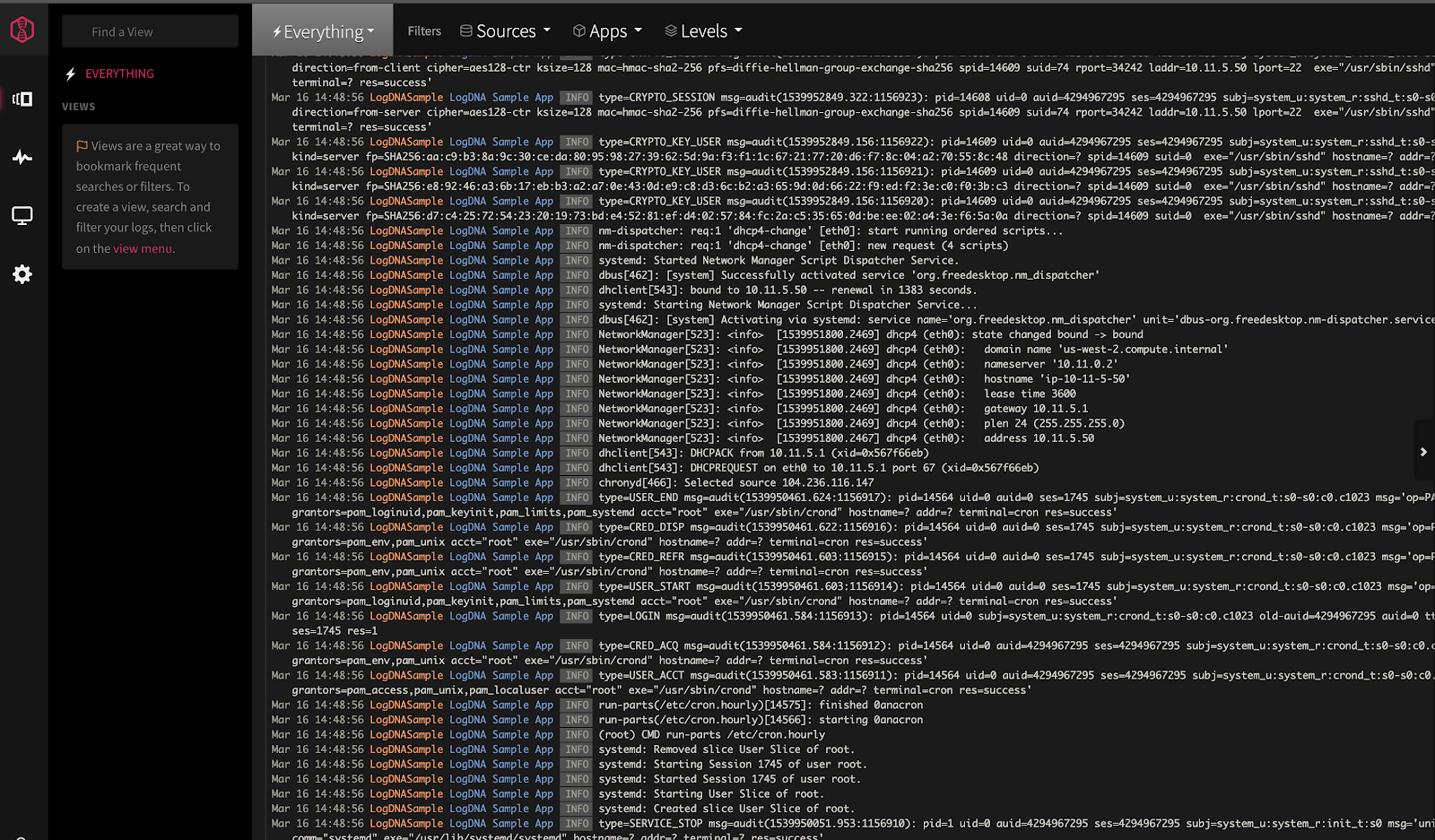
All logs are clearly visible and itemized. When you select a log line, you can view all of the meta field information that was logged at that time:
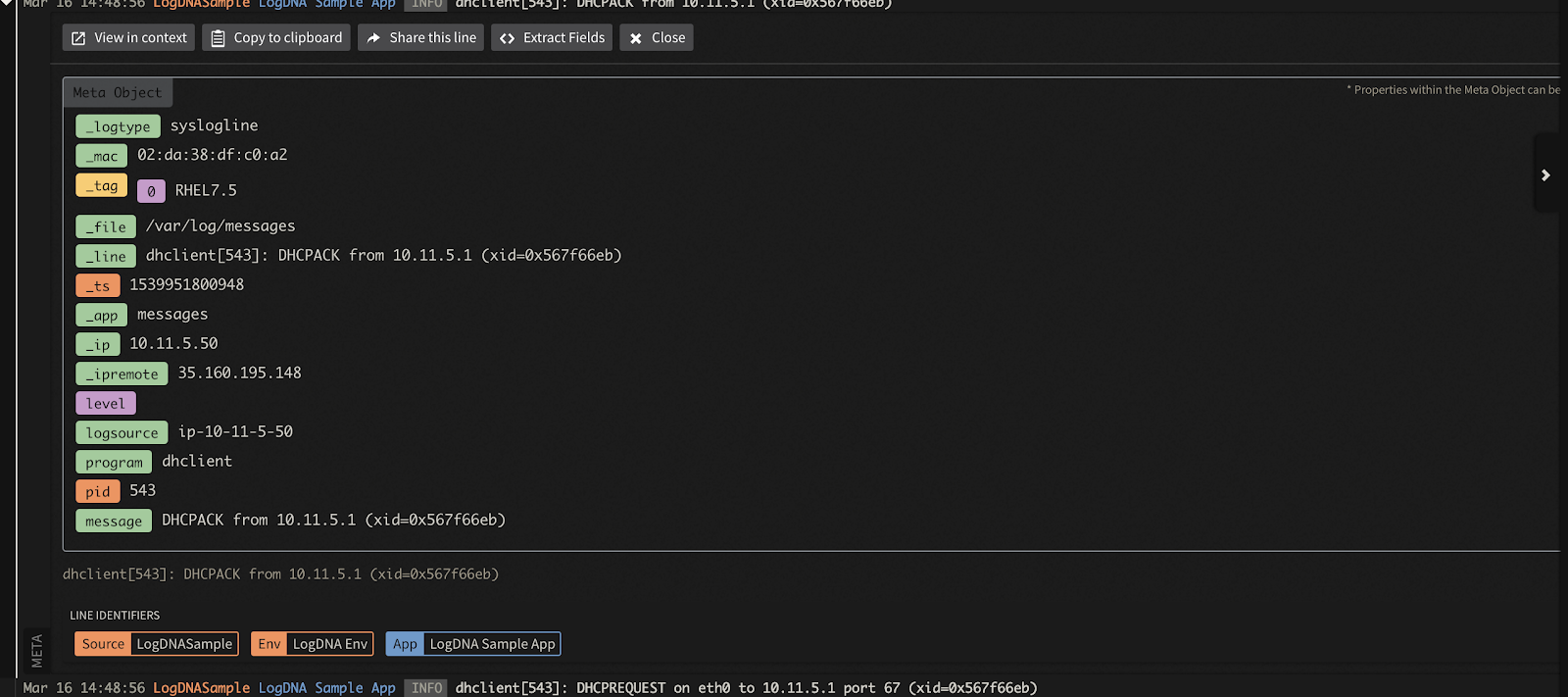
Next, we’ll show you how to enroll a new application in the platform and run it in production mode so that we can perform tests and log events.
Enrolling a New Application
LogDNA supports ingestion from multiple sources using the LogDNA Agent, Syslog, Code Libraries, and APIs. In this example, we will log data from a Node.js application sourced from this repo.
You can follow the installation process as explained in the ReadME. Then, you will need to hook the LogDNA logger into the Winston.js instance config.
Install the following packages:
Once you have everything configured, you will need to start the production environment server.
You want to get as close to a production instance even when connecting to MongoDB or Social Login; for example, using the .env options for, MONGODB_URI, FACEBOOK_ID and FACEBOOK_SECRET. We recommend a production ready MongoDB server from MongoDB Atlas and using a testing account for Facebook Login.
You will have to build the assets first and then start the server. This can be done with the following commands:
You will see the following events logged into the console:
Testing the Environment with LogDNA
If you try to sign up a new account with email, you may encounter an internal server error when navigating to the account page:

Currently the logger does not capture any information about the error. Let’s use the logger to record those error messages so we can inspect them in the LogDNA dashboard.

Alerts
You can set up alerts so that certain log lines trigger notifications. This is done in the alerts sidebar option:
Let’s first create an alert that triggers an email after at least 5 events are logged. When you click ‘Add Preset’ you will need to fill in those details:
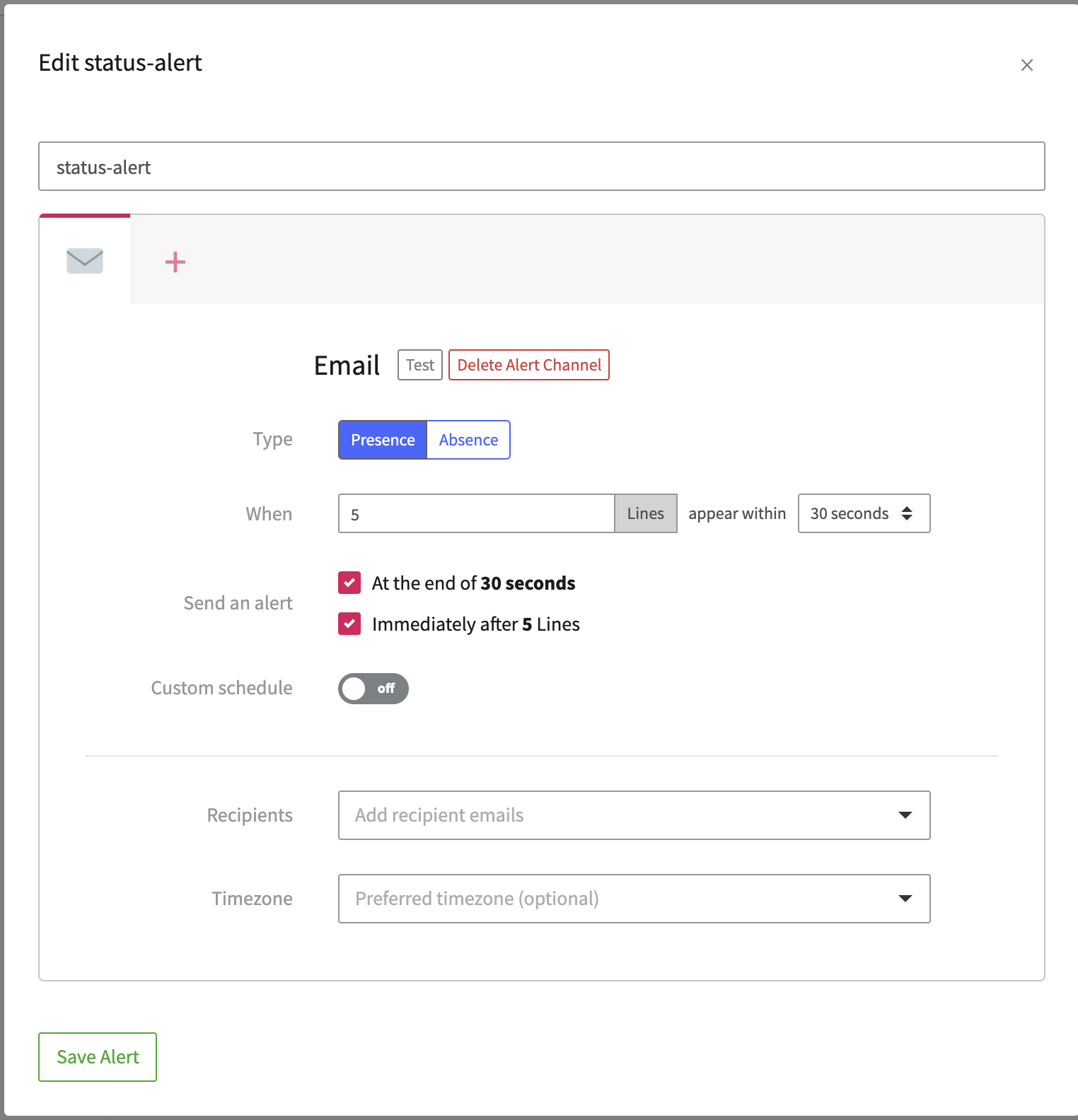
Once created, you want to attach a View into it. A View is a saved filtering of logs based on some criteria like status codes for 400, 500, or other errors. In this example, we create a View for the template errors we found earlier.
On the Logs view, you want to select the appropriate filters on the top bar. Select host=localhost, Application=Typescript-Node and level=Error and click on the Unsaved View -> Save as a new view and select the Alert we created before.
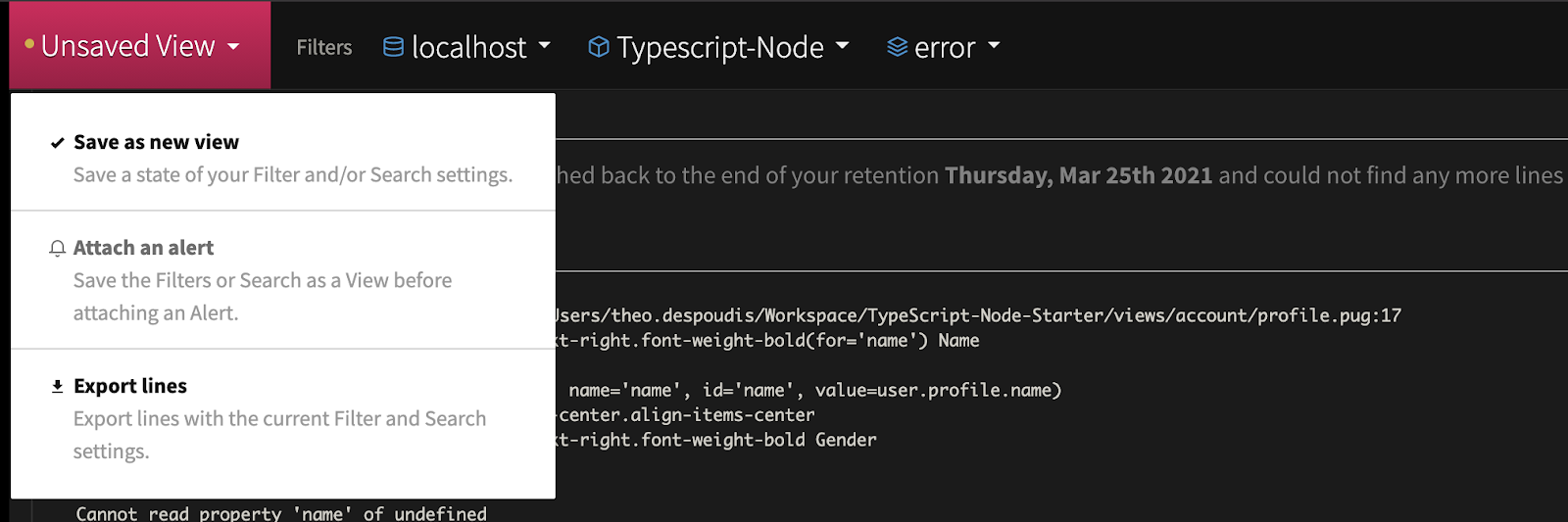

Let’s add another one for specific status codes like 304, 400, and 500. You may want to use the query language at the bottom search bar. Enter the following query and save it as new View:
The view modal shows the parameters you selected and which alert to use:
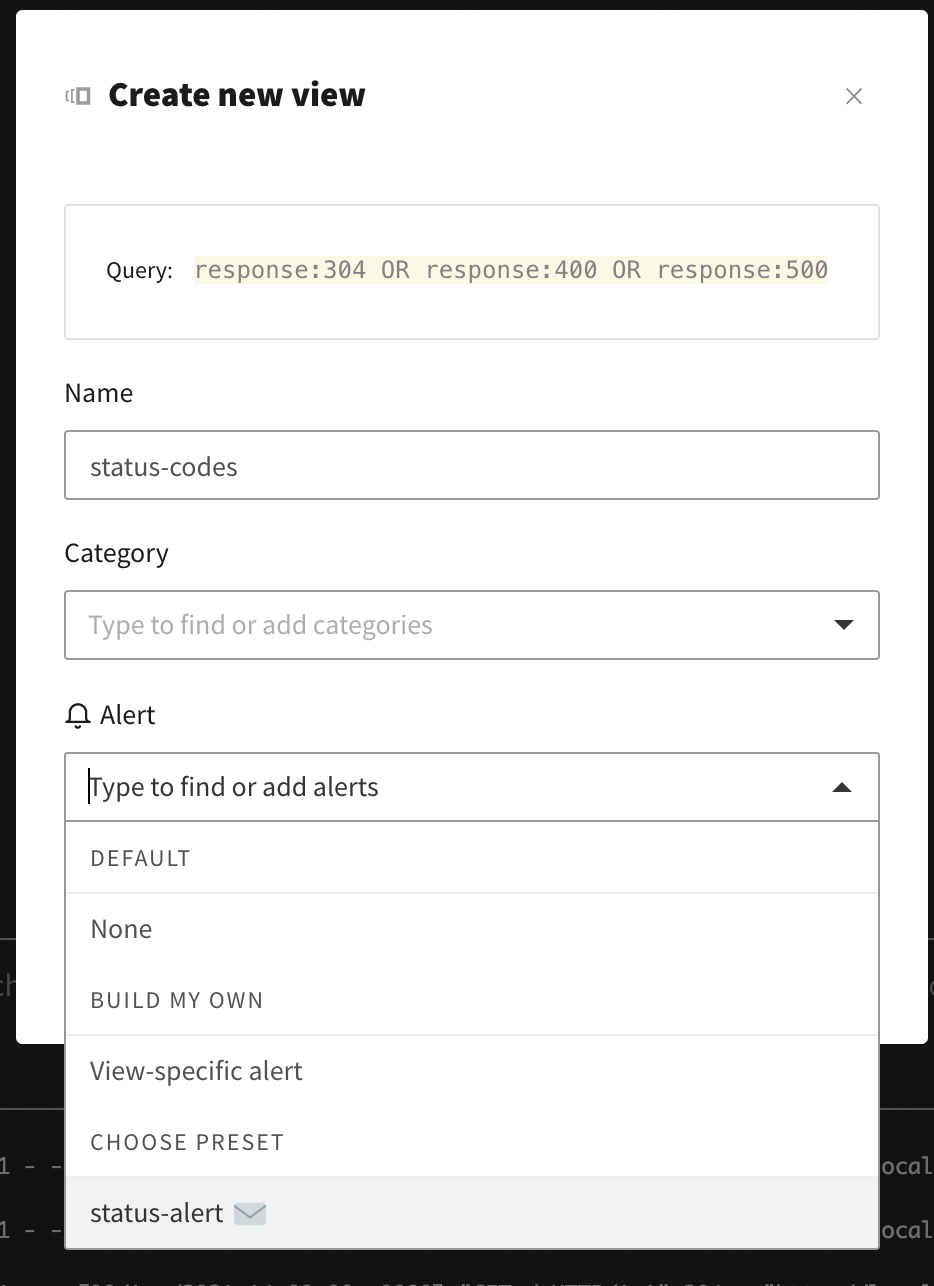
Now you will get email notifications when you exceed those alert thresholds:
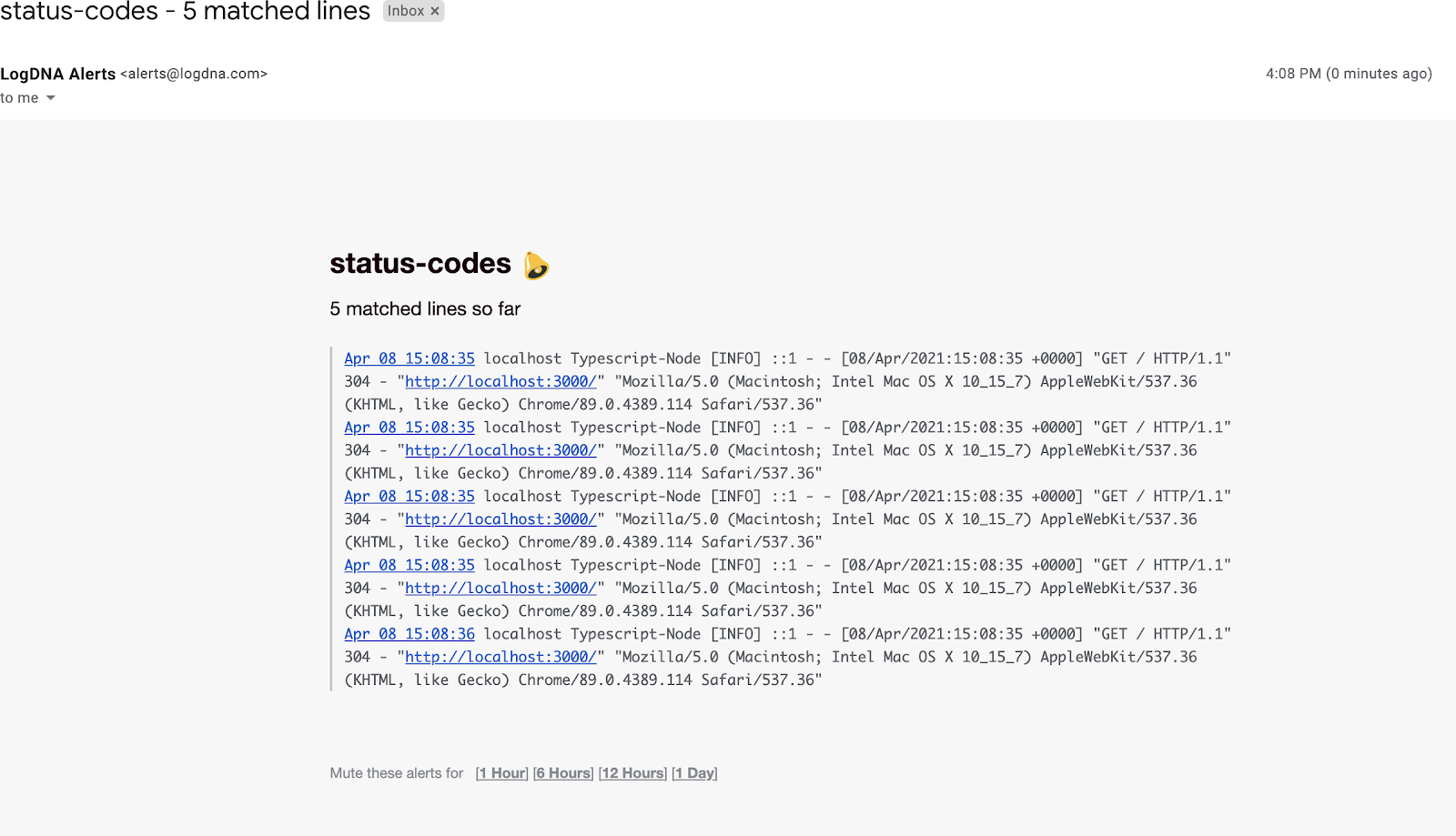
Sharing Views with Developers
With some views available you can now share them with developers or related parties so they can inspect them on their own. You can use the Export Lines option to grab an export when selecting an existing View from the top Bar:
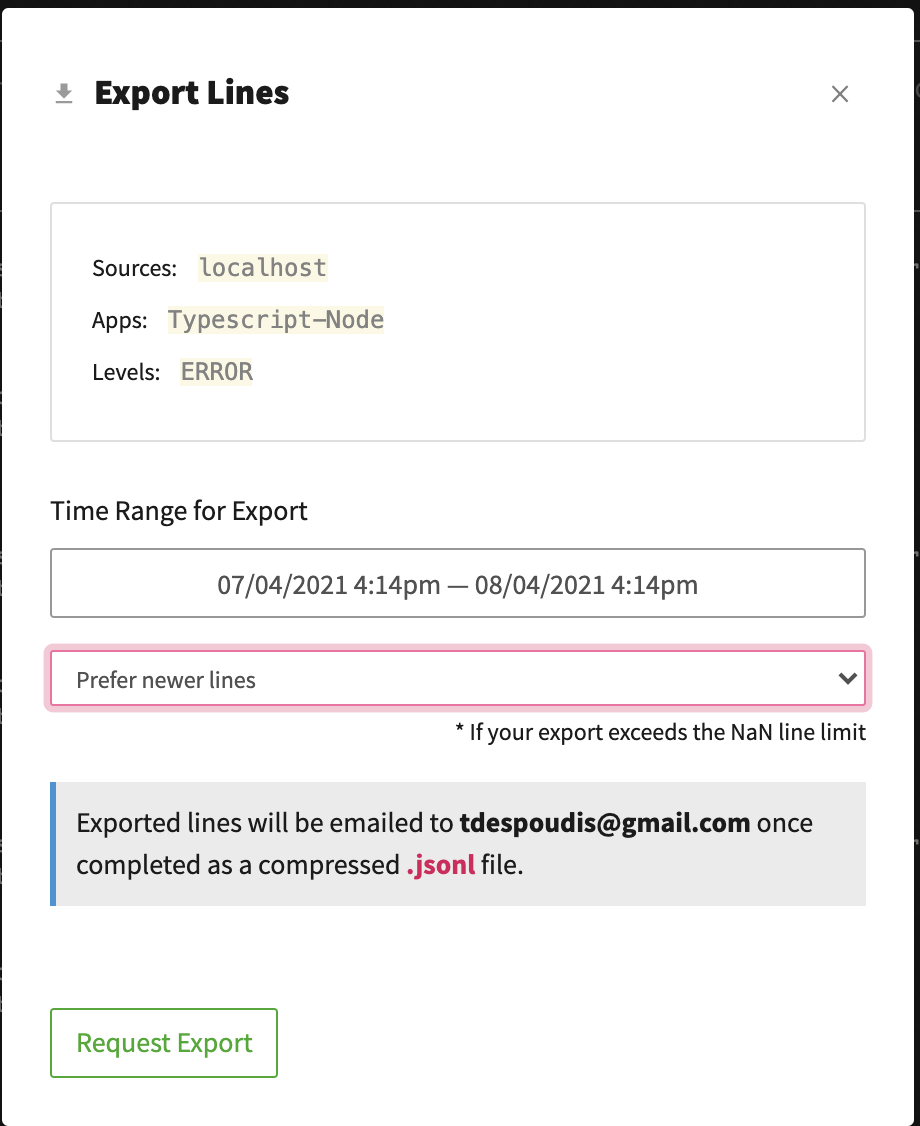
You will get an email containing the lines in jsonl (JSON Lines) format. Send those files to the developers; they can inspect them with the following command:
If the developers have access to the Dashboard, you can share the link to the view as well. This is an example link:
https://app.logdna.com/b5a09b29ad/logs/view/d02237cb23
How to Exclude Log Lines Before and After Ingestion
When logging information in requests – especially for environments that mimic the production site – it’s significant not to capture any sensitive data such as login credentials or passwords. You can define rules, using regex (regular expressions), to control what log data is collected by the agent and forwarded to LogDNA to prevent those kinds of events from ever appearing in the LogDNA dashboard (check out this GitHub repo to learn how).
You may also want to filter out logs by sources, by app, or by specific queries using an Exclusion Rule. These are great for excluding debug lines, analytics logs, and excessive noise from logs that aren’t useful. You can still see these logs in Live Tail and be alerted on them if needed but they won’t be stored. To start, find the Usage-Exclusion Rules option in the sidebar:

Then you will need to fill in some information about the rule. You may want to find specific log lines that match the query first. Here is an example with a message matching the following lines:
This tells us to ignore lines with messages containing the strings password= or email=. Note that this will not capture those lines; so if you want to capture the information but not the sensitive data, you will need to redact it from the application.

Examining automated tests for failures
You are not limited to using the logger instance for runtime information capture. You can use it for CI/CD pipelines and test cases as well. This would give you a convenient way to capture test results all within the LogDNA dashboard.
Because you may want to capture specific information during a CI/CD pipeline, you want to attach a meta tag or a different level on it. At first, when you run test under CI/CD, you want to set a CI=true environment variable and pass it into the logger instance config:
Then you may want to create a new View with that Environment. In order to capture errors you may want to configure a custom reporter to log any failed test cases. This is beyond the scope of this tutorial, but you can see an example using Jest here:
https://jestjs.io/docs/configuration#reporters-arraymodulename--modulename-options
Once you get those logs captured, you can connect them with Alerts and Boards as well. This will help you visualize these errors and correlate them with recent code changes.
Conclusion and Next Steps
In this article, we saw how to leverage the LogDNA platform for QA and staging environments. As a rule of thumb, those environments should match exactly the production versions in both functional and non-functional requirements. Additionally, when running integration and system tests, those test logs should be queryable in case of failures. Using LogDNA Alerts, Boards, Graphs and Screens can help catch and visualize those errors in correlation to any recent code changes. Lastly, using saved Views, you can delegate important information to developers when trying to discover significant problems or performance bottlenecks. Feel free to trial the LogDNA platform at your own pace.
Similar blog posts



