
The journey to production AI: Five steps for SRE and platform teams
In a recent webinar, The Journey to Production AI, Andre Elizondo walked through what separates a working agent demo from an agent worth trusting on a 2 a.m. page. Live polls during the session put numbers behind a pattern most platform teams already feel.
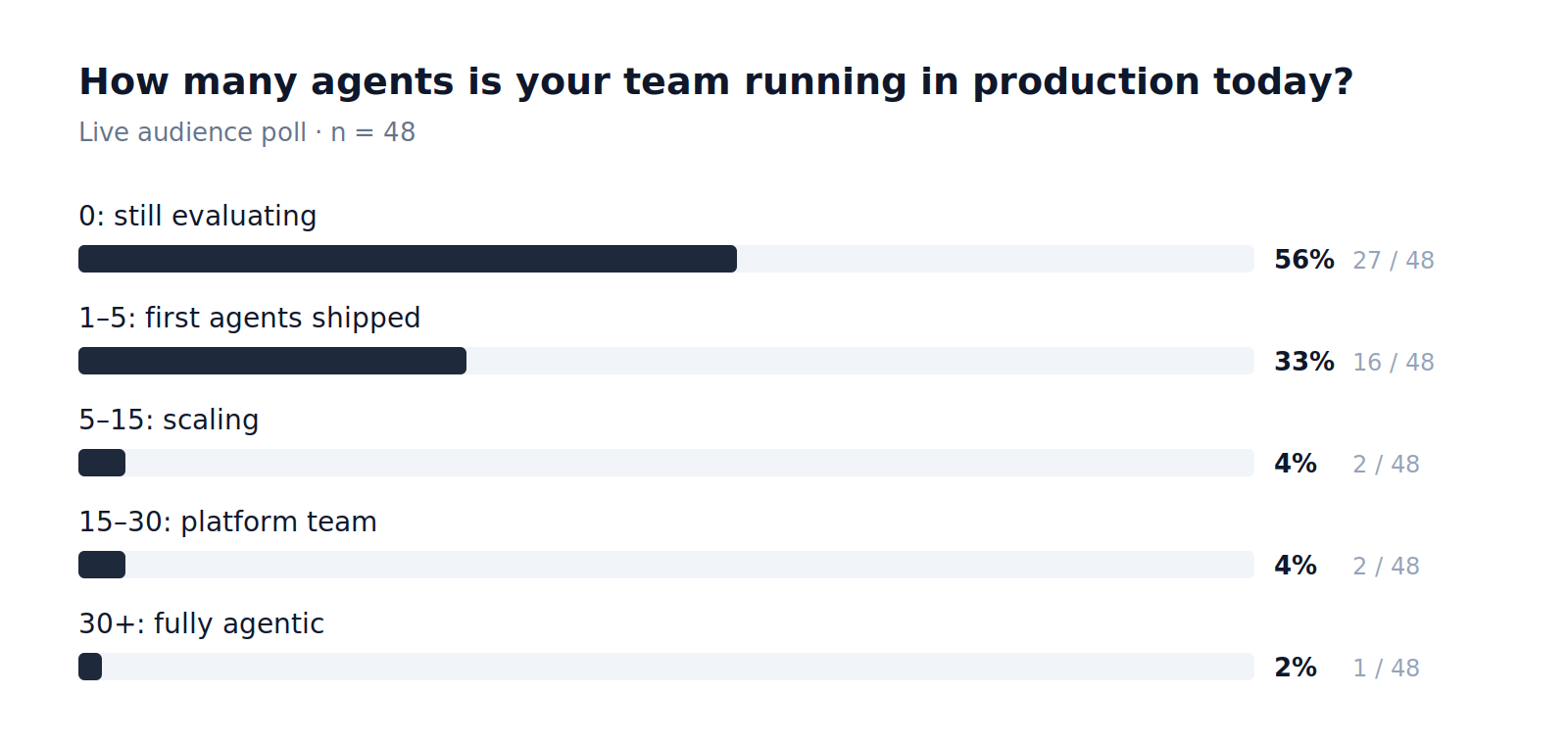
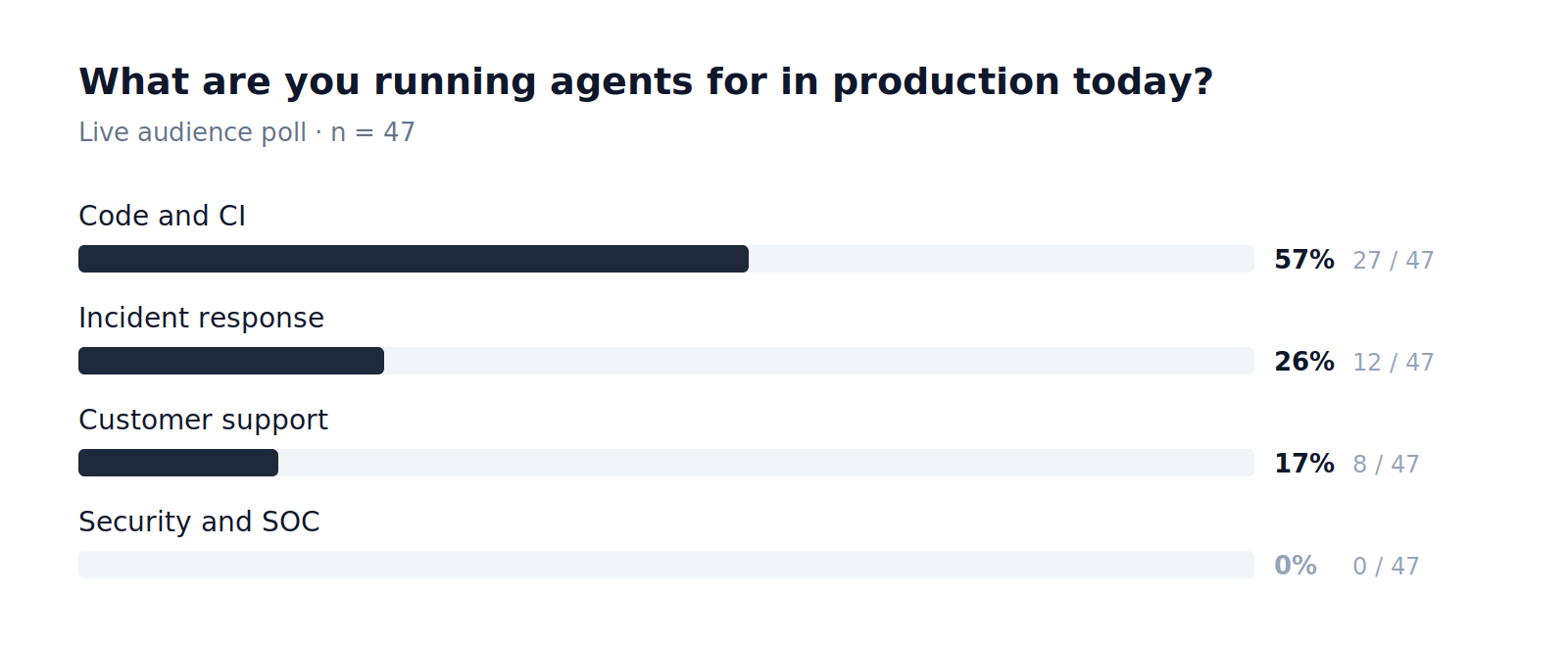
Most teams are early. The ones who are further along did not get there by shipping a flashier demo. They got there by treating production AI as a platform problem.
What "production AI" actually means
AI in production, for production. Two requirements, both load-bearing.
Production-grade. The agent has to survive scale. One investigation is a demo. A thousand investigations is a system, and a system has to handle context limits, hallucinations, and token economics without falling over. Frameworks like LangChain ship the agent. They do not ship the operating environment around it.
For production. The agent is doing the work an SRE or platform engineer would do, in environments where mistakes have consequences. Confidently wrong is worse than unhelpful. The same care a human would apply to a config change has to be encoded into how the agent behaves.
Three problems consistently get in the way:
- Drowning in context. Production telemetry is verbose, fragmented, and spread across systems. Stuffing all of it into a context window is expensive, slow, and counterproductive.
- No memory. An agent that re-derives its understanding of the environment on every run is operating like a temp who quits after every shift. The same investigation pattern gets rediscovered, paid for again, and eventually missed.
- No governance. Without audit trails, versioned workflows, and graduated trust, there is no answer to "what did the agent do, and was it allowed to do it?"
What this points to is a production agent that is trusted, repeatable, and observable. The five steps below are how to get there.
Five steps from experimentation to autonomous ops
1. Choose a harness, not just a framework
Frameworks are Lego blocks: maximum flexibility, no opinions. A harness brings opinions about how a production agent should be structured, how it observes itself, how it persists memory, how it asks for help. The harness is what keeps you from starting from scratch on agent number two.
2. Pick a problem that is painful, bounded, and reversible
- Painful: something that runs often enough to feel the toil. Incident investigation is the canonical example.
- Bounded: clear inputs, clear outputs, ideally something with an existing runbook. No boiling the ocean.
- Reversible: day-one agents propose, they do not act. A suggested rollback or a draft config change beats an autonomous restart.
3. Engineer context, do not dump it
Three rules carry a lot of weight:
- Tokens are a finite, billed resource. Every token in the context window adds latency and cost.
- Relevance beats relatedness. "What changed in checkout in the last hour" beats "all logs in this time range."
- Structure beats volume. High-quality, curated signal outperforms a firehose, even when the firehose technically contains the answer.
4. Engineer memory so the agent is not an intern
Cold-starting on every task is the same anti-pattern as hiring temps. Service relationships, prior incidents, what is typical for this environment: those belong in persistent, prioritized memory, not re-derived on every run. The harder design question is what to remember and how to rank it. General-purpose memory MCP servers offer flexibility, but they push that work onto you.
5. Earn autonomy in stages
Three steps, in order:
- Co-pilot: human approves every action. Day-one default for anyone touching production.
- Pattern recognition for approved tasks: workflows the agent has demonstrated competence on get a longer leash.
- The "dark factory" of ops: the agent operates autonomously, with full audit visibility for review and compliance.
Where Mezmo fits
Mezmo builds this stack in two layers, one open source and one platform.
AURA (open source, Apache 2.0). AURA is a purpose-built agent harness for SRE and platform engineering. Workflows are defined in TOML. Observability is on by default. The agent is model-agnostic across OpenAI, Anthropic, Bedrock, Ollama, anything that exposes an OpenAI-compatible endpoint, plus the broader OpenRouter catalog. AURA exposes its own OpenAI-compatible API, so it slots into LibreChat, Open WebUI, or whatever chat interface the team is already using. The repo is at github.com/mezmo/aura.
The Mezmo platform. While AURA handles orchestration, the platform handles the parts that get harder at scale:
- Signal curation: the platform generates briefings the agent consumes over MCP, so context engineering becomes a tool call, not a custom pipeline.
- Opinionated memory (early access): memory tuned for observability and ops tasks, exposed over MCP, designed to compound rather than reset.
- Graduated workflow visibility (early access): the visibility and controls that let teams move agents up the autonomy ladder when the data supports it.
Both layers are composable over MCP. Teams using another harness can run Mezmo as the curation and memory layer; teams on Datadog or ClickHouse can point AURA at those tools without changing harnesses.
From the Q&A
A few exchanges practitioners will recognize.
Best first use case for a team with zero agents in production? An internal SRE assistant. Stand up AURA, give it tools to interpret the environment, and let the rest of the organization ask it questions. After that, incident investigation is the next obvious step: high-frequency, bounded, and reversible if you stop short of remediation.
A Mezmo-internal use case worth noting: agents that maintain their own runbooks. When an investigation surfaces a runbook gap or a stale step, the agent opens a PR against the runbook it later consumes. Closed loop, self-improving.
How do you know context changes are helping, not hurting? AURA emits OpenTelemetry across its planning, self-evaluation, and self-correction cycles. Confidence scores between runs, token utilization per task, outcome metrics observed out-of-band: all of it is available for evaluation in any OTel-compatible backend, with built-in views in the Mezmo platform.
What to do with this
For the 56% still evaluating, the path forward is short.
- Pick one workflow: painful, bounded, reversible. Internal SRE assistant or incident investigation are the strongest starting points.
- Choose a harness with opinions: not a framework that pushes the operating environment back onto you.
- Instrument from day one: the graduation from co-pilot to autonomy is only safe with the data to support it.
Start building: AURA is on GitHub at github.com/mezmo/aura.
For platform sandbox access, design partner conversations, or feedback on AURA, reach out to andre.elizondo@mezmo.com.
Table of Contents
Share Article


RSS Feed

Similar blog posts



