
How to Use S3 Access Logs
• Learn how to obtain S3 Access logs
• Learn how to make S3 Access logs readable for analysis
Amazon Simple Storage Service, aka S3, is one of the most popular and user-friendly services on AWS. S3 allows file storage with scalability, and it also supports access auditing through S3 access logs, helping you avoid performance and security issues. It’s worth mentioning that many resources are available that enable S3 to be used in different ways, such as versioning, website hosting, and logs for auditing and security visibility. This tutorial will show you how to use S3 access logs via code as part of your broader telemetry pipeline.

AWS S3 Access Log Content
AWS S3 provides log information regarding access to buckets and their objects. These s3 logs capture data like: bucket owner, bucket, time, remote IP, requester, operation, request ID, requestURI, key, error code, bytes sent, HTTP status, total time, object size, turnaround time, user agent, referrer, host ID, version ID, cipher suite, signature version, authentication type, TLS version, and host header.
When access to an object is requested, users can use this data to identify the origin of the request. You can check if unauthorized users have accessed any resources or spot an object with an unusually high number of downloads. You can also assess whether file retrieval times meet your app’s expectations. In addition, this security log data helps illustrate how applications interact with S3 resources over time.
We’ll show you how to obtain and format these S3 access logs for analysis in the sections below.
Enabling Logging for Bucket Objects
To enable s3 logs, first create one bucket for your files (objects) and another bucket to store the access logs—both should be in the same AWS region. It’s best practice to avoid storing logs in the same bucket you’re monitoring. If an issue occurs with the main bucket, the logs may also be compromised, making it harder to diagnose the error.

After creating the buckets, navigate to the Properties of the bucket that stores your files. On the Properties page, click the Edit button in the Server access logging section. Enable logging, then click Browse S3 to select the log destination bucket.
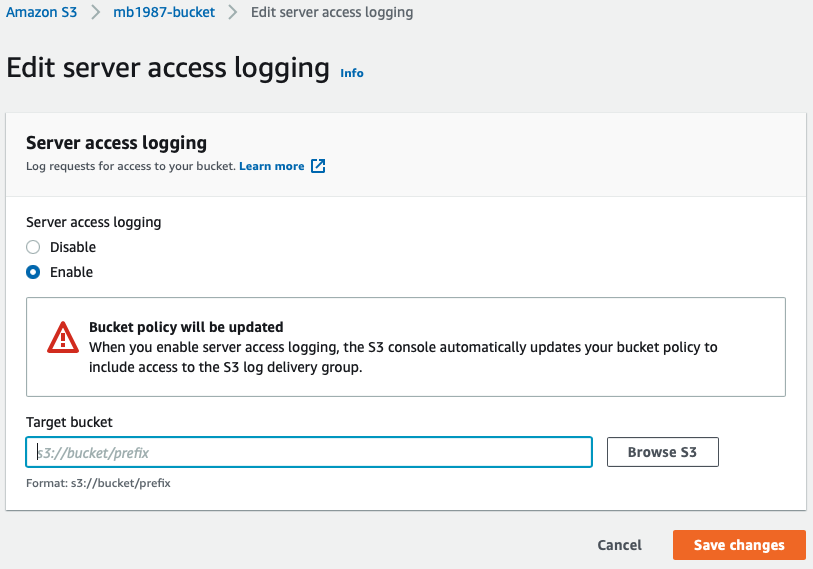
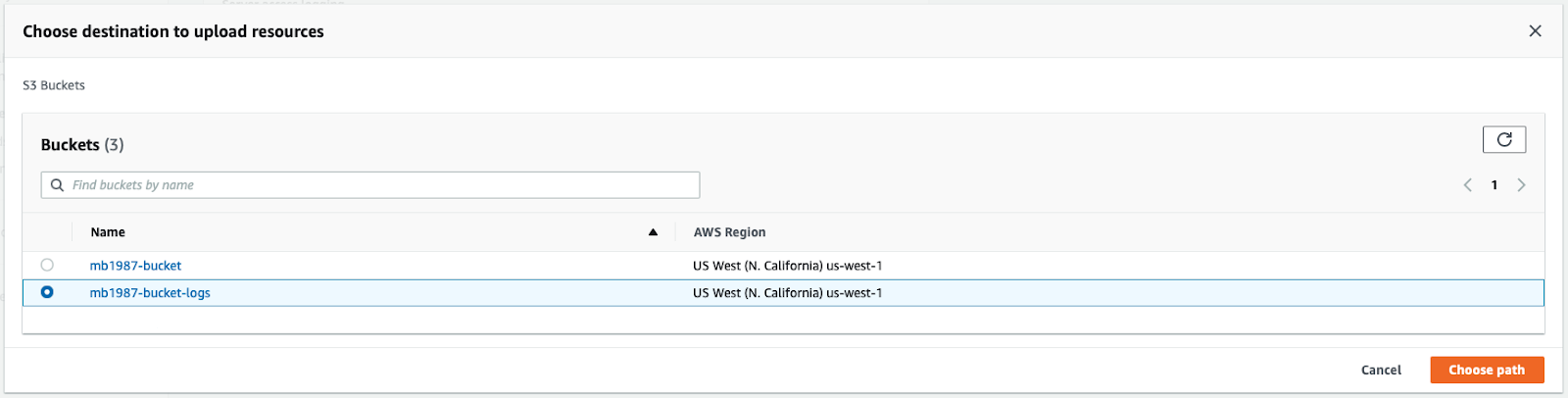
In the modal, select the appropriate bucket and click Choose path. Back in the form, click Save changes. You’re now saving S3 access logs automatically for object usage tracking.
Testing Logging
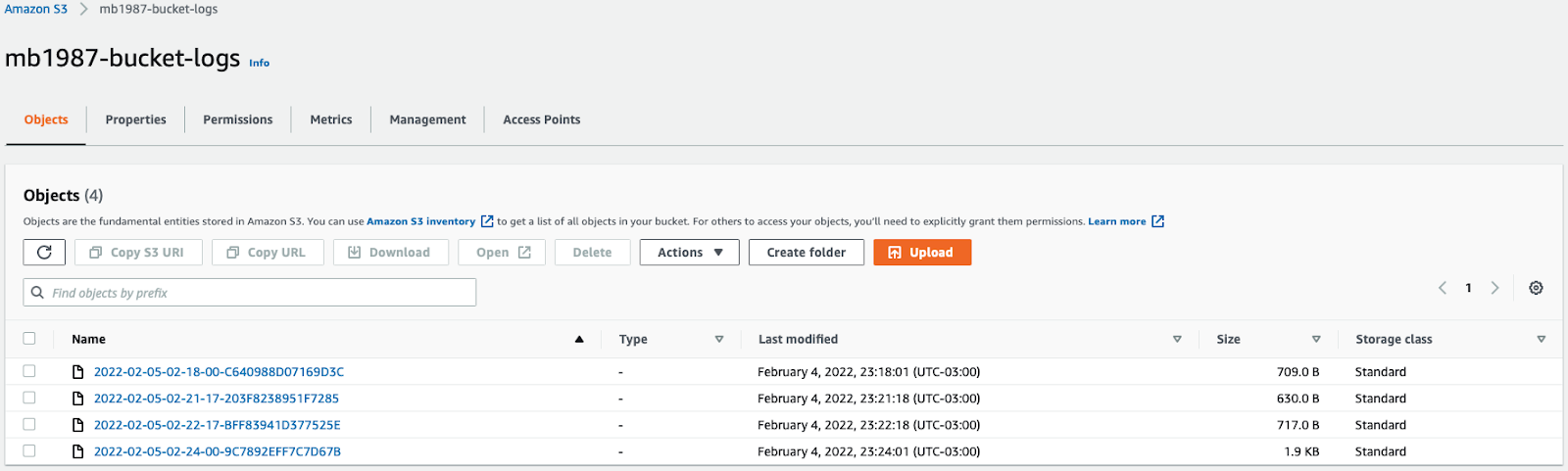
To verify the setup, upload or delete files in your monitored bucket. These actions will generate s3 logs. You can open, download, and remove files to trigger entries. Then, visit the bucket where your logs are stored and wait a few minutes for the data to appear.
Once logs are generated, you’ll see entries related to each interaction, including object retrieval, deletion, and policy versioning. These entries act as security logs you can later parse and analyze.
Log Data Samples
Let’s take a look at some sample s3 logs to understand their structure and content. For example, here’s a delete operation log:
ce6f2c543de2b9a3a4fdf21d56e95135af4045032a9157cb2fdb1a4854c73110 mb1987-bucket [05/Feb/2022:01:09:08 +0000] 191.XXX.XXX.216 ce6f2c543de2b9a3a4fdf21d56e95135af4045032a9157cb2fdb1a4854c73110 BW21GJ60HATK1VCR REST.POST.MULTI_OBJECT_DELETE - "POST /mb1987-bucket?delete= HTTP/1.1" 200 - 5100 - 802 - "-" "S3Console/0.4, aws-internal/3 aws-sdk-java/1.11.1030 Linux/5.4.172-100.336.amzn2int.x86_64 OpenJDK_64-Bit_Server_VM/25.302-b08 java/1.8.0_302 vendor/Oracle_Corporation cfg/retry-mode/standard" - NLZUuMfnLn6Kq3LKEB5GFRNAVEo9cy/BR5bmzhy4dXWD0ogwa6Q71IzUbJKlidFbVwUiRR9jk9w= SigV4 ECDHE-RSA-AES128-GCM-SHA256 AuthHeader s3-us-west-1.amazonaws.com TLSv1.2 -
And this is get:
ce6f2c543de2b9a3a4fdf21d56e95135af4045032a9157cb2fdb1a4854c73110 mb1987-bucket [05/Feb/2022:01:08:58 +0000] 191.XXX.XXX.216 ce6f2c543de2b9a3a4fdf21d56e95135af4045032a9157cb2fdb1a4854c73110 MSAHCXNXGA3NJY9V REST.GET.BUCKET - "GET /mb1987-bucket?list-type=2&encoding-type=url&max-keys=1&fetch-owner=true&delimiter=&prefix= HTTP/1.1" 200 - 768 - 106 105 "-" "S3Console/0.4, aws-internal/3 aws-sdk-java/1.11.1030 Linux/5.4.172-100.336.amzn2int.x86_64 OpenJDK_64-Bit_Server_VM/25.302-b08 java/1.8.0_302 vendor/Oracle_Corporation cfg/retry-mode/standard" - X4VZjjWLHbLLApCiTeXoulUTQmYYduxisCY8E6se4YZx7FRBX6KsSd4lG+VwfrpgLqQXTdPbTGE= SigV4 ECDHE-RSA-AES128-GCM-SHA256 AuthHeader s3-us-west-1.amazonaws.com TLSv1.2 -
These logs show rich metadata about actions performed, user agents involved, and AWS request types. Understanding this format is key to building any automated S3 log parser or audit trail.
Download Logs
To process S3 access logs, you'll need to download them locally. AWS SDK for S3 provides methods for retrieving objects programmatically. Here, we’ll use AWS SDK for Ruby.
AWS SDK S3 for Ruby can be installed via gem:
$ sudo gem install aws-sdk-s3
Once you have it installed, you can either use IRB code or run Ruby code. Choose your preferred method, and don't forget to get your credentials from IAM. You will need an access key ID and a secret access key. Now, create a new folder called logs to store the logs locally.
require 'aws-sdk-core'
require 'aws-sdk-s3'
# Change the text and for your credentialsaws_credentials = Aws::Credentials.new('', ''
s3 = Aws::S3::Resource.new(region: 'us-west-1', credentials: aws_credentials
# Change mb1987-bucket-logs to the name of the bucket used to store the logs.bucket_logs = s3.bucket('mb1987-bucket-logs'
bucket_logs.objects.each do |log| log.download_file("./logs/#{log.key}")end
Now all your s3 logs will be downloaded and saved inside your logs folder. Consider implementing log rotation practices if you're dealing with high log volume to keep storage usage efficient and reduce clutter.
Exporting S3 Access Logs to JSON
By default, S3 access logs are not in a structured format like JSON. You’ll need to wrap log content in your own structure for readability and downstream processing.
The following code will read each downloaded log, select key, remote IP, and operation storing in a list that will be exported as a JSON file.
require 'json'
log_list = [
Dir.children('./logs').each do |filename|
file = File.open("./logs/#{filename}")
log_content = file.read.split(" ")
log_list << {
key: "#{filename}",
operation: "#{log_content[7]}", # Remote IP position
remote_ip: "#{log_content[4]}" # Operation type position
}
file.close
en
File.open('log.json', 'w') do |file| file.write(JSON.pretty_generate(log_list))
en
The JSON file (called log.json) will look like this
[
{
"key": "2022-02-05-04-22-39-73EAF9FB803326E0",
"operation": "REST.GET.BUCKET",
"remote_ip": "191.XXX.XXX.216"
},
{
"key": "2022-02-07-01-15-03-8F0F6DFD2FDABC7A",
"operation": "REST.HEAD.OBJECT",
"remote_ip": "191.XXX.XXX.216"
},
{
"key": "2022-02-07-01-30-10-4A1C6739831927C5",
"operation": "REST.GET.POLICY_STATUS",
"remote_ip": "191.XXX.XXX.216"
}
]
Conclusion
Reading AWS S3 logs manually is possible, but not always efficient. You'll need to fetch, format, and parse S3 access logs before they become useful. AWS offers tools like Amazon Athena to query logs or CloudTrail to complement them. You can also integrate a telemetry pipeline tool like Mezmo for enriched insights and automated analysis.
As a developer or DevOps engineer, understanding how to work with security logs and implement log rotation and analysis strategies is key to securing and scaling your cloud environments.
Related Articles
Share Article


Ready to Transform Your Observability?
- ✔ Start free trial in minutes
- ✔ No credit card required
- ✔ Quick setup and integration
- ✔ Expert onboarding support
