
Why and How to Archive and Restore Logs from S3 Buckets
• Understand why you may want to use S3 for log archiving and log data restoration
• Learn how Mezmo can help you do it
As a low-cost, flexible, cloud-based storage service with virtually unlimited scalability, Amazon S3 is a great place to store archived log data — especially s3 access logs that support auditing, compliance, or security reviews.
And with Mezmo, formerly known as LogDNA, using S3 as a log archiving solution is even better. That’s because Mezmo can automatically archive logs to S3 and restore them from S3 without requiring any particular S3 expertise on the part of users.
This blog post explains why you may want to use S3 for log archiving and log data restoration and how Mezmo can help you do it.

Amazon S3 for Log Management
S3 is the primary object storage service in the Amazon cloud, storing virtually any data flexibly.
When you use S3, you create storage “buckets.” You can place almost any type of data into each bucket. S3 buckets are like folders in a file system, but they are more flexible because S3 doesn’t require you to organize your object data in any particular way. You can dump any files (or other types of objects) that you want into a storage bucket and then access them when you need them.
S3 is a great storage solution for many types of data, not just logs. But for log management and archiving in particular, S3 offers especially beneficial features:
- Cost efficiency: S3 is available in several different storage “classes,” each with other price points and levels of performance. The lower-priced classes are attractive for log archiving because they cost just pennies per gigabyte per month. Although there may be some delay in accessing data from these storage tiers, that’s typically not a significant issue for archived security logs, which you are unlikely to need to access quickly (if at all).
- Scalability: Each S3 bucket that you create can store up to 5 terabytes of data, and you can create as many buckets as you want, making S3 a highly scalable storage solution that can accommodate as much archived log data as you need.
- Data lifecycle management: You can use lifecycle configurations to automate data management inside S3 — convenient if, for instance, you want to delete archived log files automatically after a certain period has passed. This supports log rotation best practices by automating archival and cleanup.
Mezmo and S3: Better Together
If you want to use S3 for log management, nothing stops you from manually uploading archived logs into S3 then restoring them manually if you need to access them later. You could also write your scripts to automate this process.
However, modern infrastructure requires a smarter solution that integrates into your telemetry pipeline, streamlining both storage and restoration.
S3 Archiving with Mezmo
However, a faster and more straightforward approach is to leverage Mezmo, which is configurable to automatically store archived log data in S3.
To do this, you need to create an S3 bucket in your AWS account, navigate to the Archiving pane of the Mezmo Web app and connect Mezmo to the bucket you created. (You can also archive log data from Mezmo to various other cloud-based object storage services, not just Amazon’s.)
S3 Log Data Restoration with Mezmo
Using Mezmo's data restoration feature, you can quickly and easily restore log data from S3, which is helpful if you’ve archived logs to the Amazon cloud and need to view historical log data. A case like this may arise if you are trying to investigate the origins of a trend you’ve noticed in more recent logs, for example, or you need to research a contextualized security incident using historical log data.
To perform S3 log data restoration, define a time and date range for the logs you want to restore within the Mezmo UI:
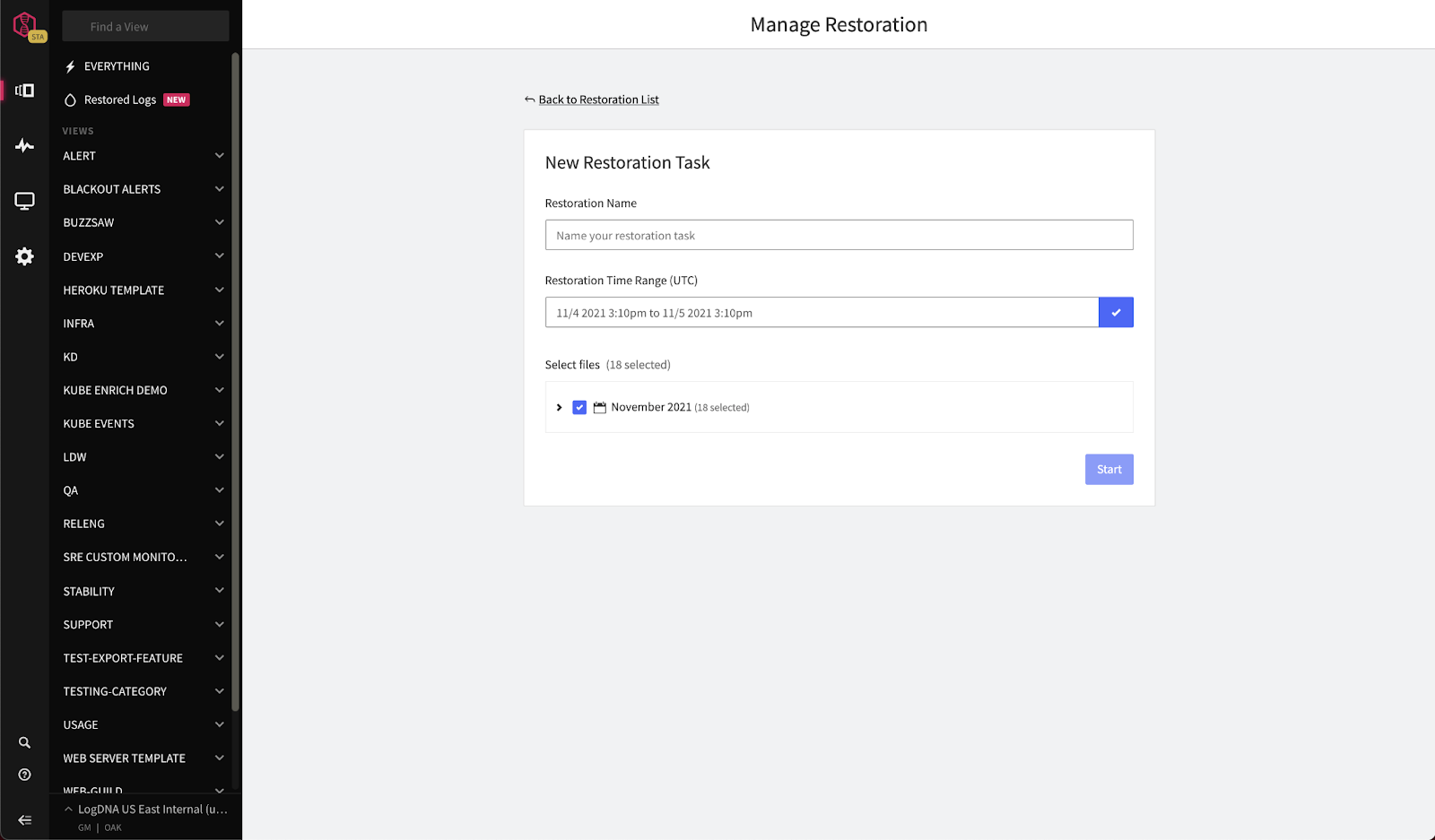
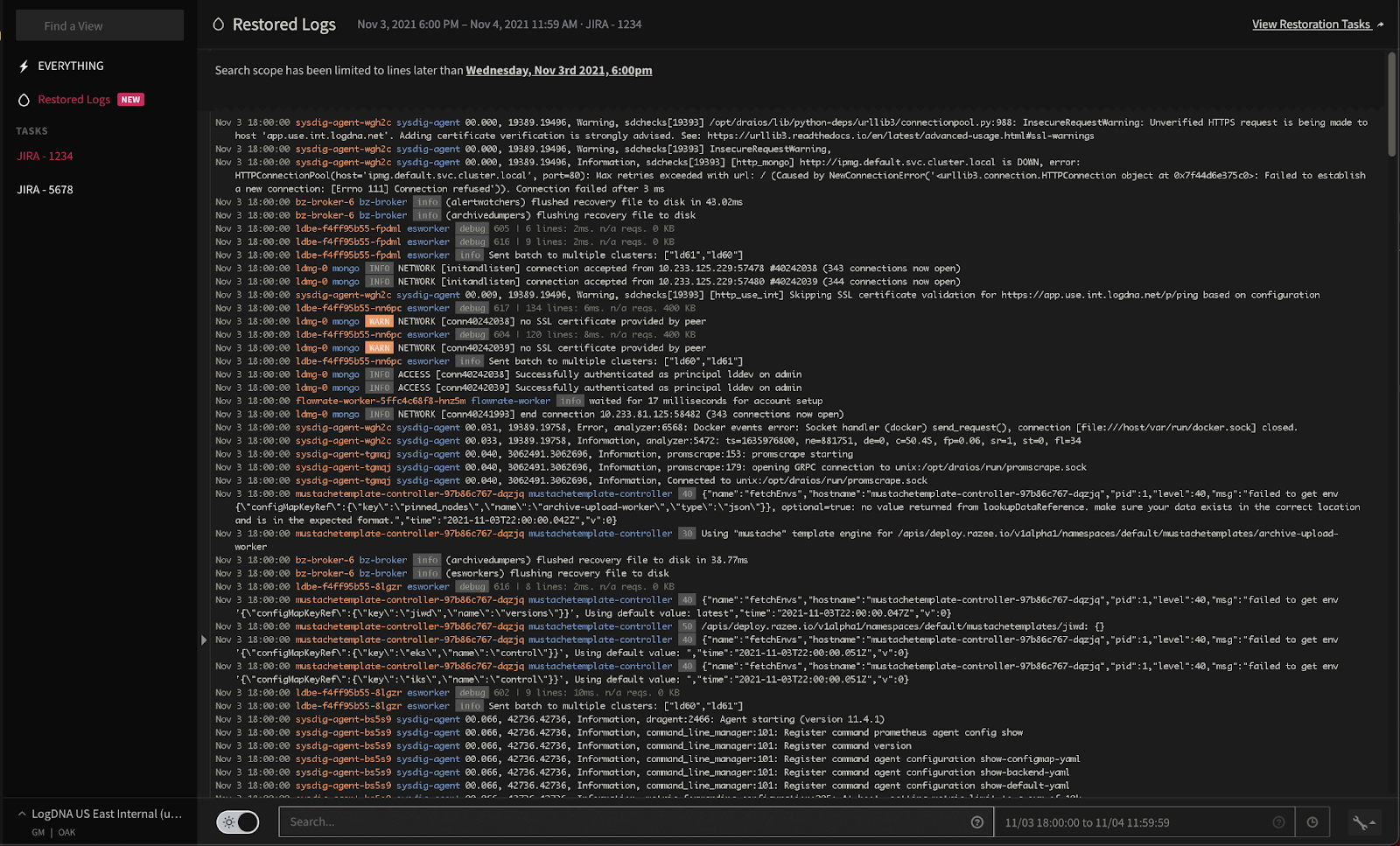
Mezmo will then display your logs directly in the UI:
Conclusion
With Mezmo, you get easy access to S3 as a log archiving and restoration solution. You don’t need to learn any special AWS tools or master the intricacies of S3. As long as you can create an S3 bucket in the AWS Console or CLI, you can use Mezmo to do everything else required to manage log data via S3 (and a variety of other cloud-based object storage services, to boot). This ensures a secure, efficient telemetry pipeline that supports both compliance and performance monitoring.
Related Articles
Share Article


Ready to Transform Your Observability?
- ✔ Start free trial in minutes
- ✔ No credit card required
- ✔ Quick setup and integration
- ✔ Expert onboarding support
