
LogDNA is now Mezmo but the product you know and live is here to stay.

For DevOps teams that want to accelerate release velocity and improve reliability, logs can unlock the insights you need to move faster. But for managers and budget owners, logging can be an unpredictable pain. Trying to estimate logging spend, especially with the adoption of microservices and container-based architecture, seems like an impossible task. This is why Mezmo, formerly known as LogDNA is focused on delivering features that help you better control the flow of log data to ensure that your teams get the insights they need, while also giving you the ability to better understand and predict spend.
To help with this effort, we released Usage Quotas earlier this year to give you further control on the amount of data your organization ingests with Mezmo. These hard and soft quotas help you stay within your budget without sacrificing valuable insight into important logs.
Today, we’re excited to release Mezmo's Index Rate Alerting feature to complete the Spike Protection bundle so that you can be notified of increases before you hit your quota.
Get Alerted on Unexpected Spikes in Ingestion
With Index Rate Alerting, you can receive notifications if the volume of indexed logs in your organization grows unexpectedly. You can monitor the index rate of logs with a fixed threshold under the Index Rate Alert Threshold feature. Set a maximum flow rate you would expect, and Mezmo will alert you if the flow rate into your index exceeds that threshold.
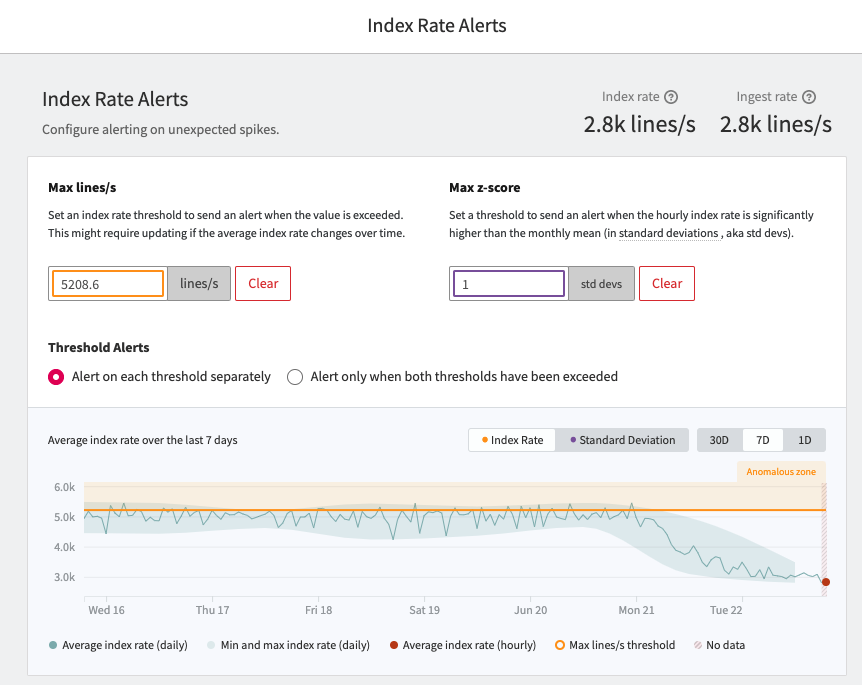
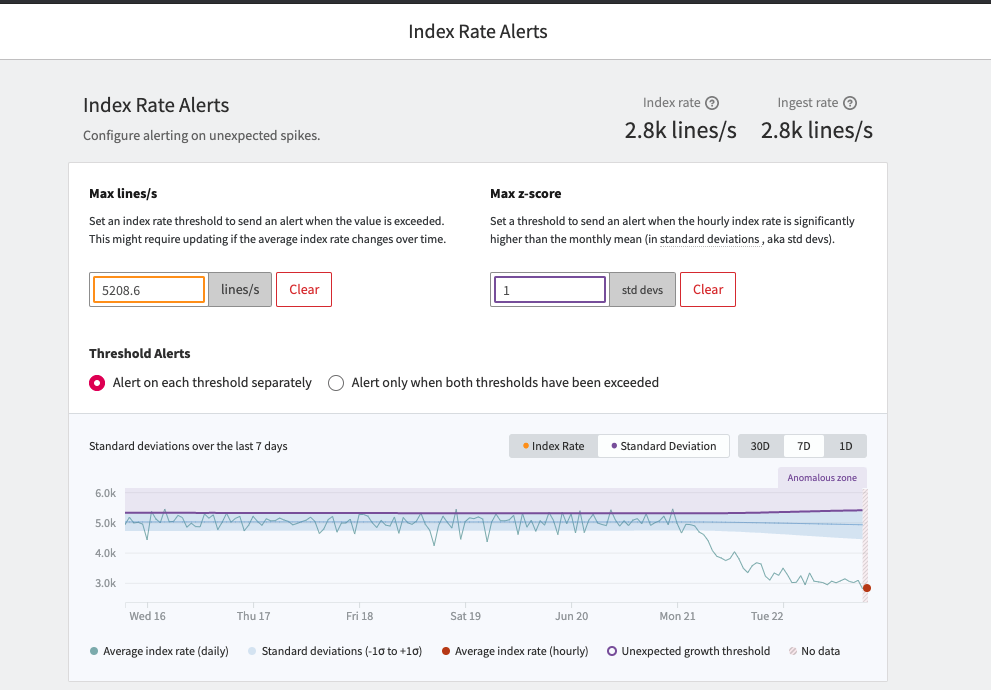
To detect anomalous increases in index rate, you can use our Standard Deviation Alert to monitor when your account is ingesting significantly more data than the norm. When you enable Index Rate Alerting, Mezmo takes your index rate data from the past 30 days to understand what is ‘normal’ for your organization, and will trigger an alert if you are sending significantly more logs than measured as normal. Please note that if you let the high volume go on for a few days, Mezmo will adjust what's ‘normal’ to a higher limit.
What Can You Do with Index Rate Alerting?
Index Rate Alerting can protect against an increase in storage costs caused by unexpected spikes in log volume. Spikes can be caused by a runaway log, someone forgetting to turn off debug, or a developer deploying a new app that is causing a large increase in log volume. Now, you can set up alerts to be notified of these changes so that you don’t exceed your set quota.
What to Do After You Get an Alert
Most admins investigate where a spike is coming from by using our visualization tools to graph all existing apps and sources to determine which one(s) are causing the spike. We included that information in the alert so that you can skip this step. Every alert triggered will come with a list of apps and sources that have seen the biggest flow rate change in the last hour to help you identify where the spike may be coming from. We will also include a list of the newest apps and sources added to Mezmo to help you better diagnose a spike, in the case the increase in log volume is from new apps deployed without your knowledge.
Bonus Feature
You've been asking for a way to see all the data associated with all the apps and sources in your organization. We couldn’t fit all of the information you might want to understand about a spike on an alert, so we built a way for you to grab this data from the usage dashboard page.

Get Started with Index Rate Alerting
Index Rate Alerting is available for all Mezmo enterprise users and is restricted to Owner and Admin roles. To learn more about how to enable this feature, please reference our documentation or get in touch with your dedicated Customer Success Manager. If you’re not yet an enterprise user and would like to learn how to get access to this feature, please email outreach@mezmo.com.
We love getting feedback about our features and how they help you better control your logs.
More blog posts



