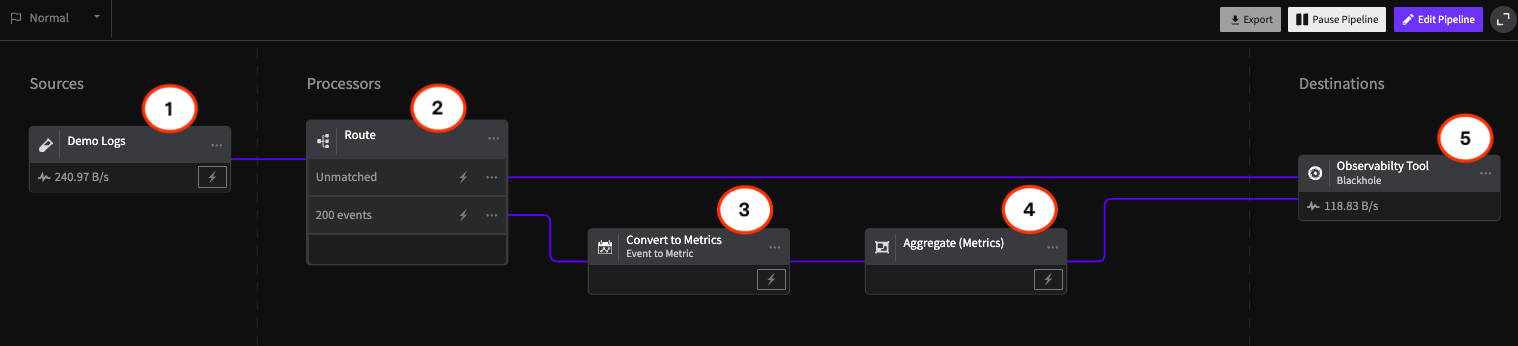
Apache Kafka Tutorial: Use Cases and Challenges of Logging at Scale
Enterprises often have several servers, firewalls, databases, mobile devices, API endpoints, and other infrastructure that powers their IT. Because of this, organizations must provide resources to manage logged events across the environment. Logging is a factor in detecting and blocking cyber-attacks, and organizations use log data for auditing during an investigation after an incident. Brokers, such as Apache Kafka, will ingest logging data in real-time, process, store, and route data. Kafka acts as a broker between infrastructure and the tools used to analyze and audit the network. Even with its advantages, Kafka has its challenges with scaling.

What Are Some Kafka Use Cases?
We can use brokers in small or large organizations. However, we often integrate systems such as Kafka when logs become fragmented as we add more infrastructure to the environment and more logs accumulate. Instead of storing individual logs from various sources, Apache Kafka retrieves them from multiple systems and stores them in one location.
Organizations that integrate Kafka need a reliable tool to pull data from each log file and process it for review. It’s also helpful when an organization needs a way to process data in real time and detect anomalies quickly. Kafka is open source, so it’s a value-added Apache system that can turn disorganized logging streams into understandable output that can be used to monitor an environment better and detect an ongoing event that should receive immediate attention. Streaming logs can make IT staff better aware of issues to be proactive with events that could result in downtime.
How Does Kafka Work?
Implementing Kafka requires the proper infrastructure. The system basics involve servers and clients to publish (write) and subscribe to (read) logs. Clients and servers communicate over the TCP network protocol, so adding the Kafka environment to your current environment only requires the right cluster and storage infrastructure. Kafka can span multiple servers in a cluster for performance. For redundancy and uptime, usually, it’s provisioned across data centers. A cluster of servers also helps with reliability, as any server can take over when one fails.
Servers are the main components that let you import and export data as a service broker that will process data in real time, but clients are the component that makes it possible. A client is the streaming service running on Kafka servers for log processing. Several client services are available since Kafka is an open source technology, including those written in Go, Python, C, and C++, enabling administrators to choose the client that works best for their environment and the server operating system.
In the logging world, every item in a log is called an event. In the Kafka environment, you have producers and consumers. A producer is a component in your infrastructure that creates logged events. The events within these logs depend on the infrastructure. For example, a database would have several logged events that define authentication, authorization, and SQL statements executed on the server. Administrators can determine if events logged by the database are successful or failed events. Logs can accumulate gigabytes (or even terabytes) of data within a day, so administrators choose the events that logs will store.
Consumers subscribe to and read log events. Neither consumers nor clients rely on the other to function. For example, if you have a Kafka server fail or taken out of service for maintenance, producers will still create events without failing due to a server going offline.
Consumers can subscribe and pull data in a first-come-first-serve order from log partitions. Partitions are “buckets” of stored log data available for consumption and streamed for further analysis. Partitions bring together the writing and reading of events, but it’s also the main issue with scalability.
What Are The Challenges With Using Kafka?
The biggest challenge for any organization using Kafka is scalability. Decoupled publishers and subscribers have their benefits, but it also causes complexity as the business grows and adds more to infrastructure. The most significant resources necessary for Kafka performance are server memory (RAM), disk capacity, and network bandwidth. As servers process more log events, send more data across the network, and more logs accrue on the cluster, administrators must provide additional resources on servers. Because of the excessive resource requirements, the costs to support Kafka don’t scale well.
Partitions hold messages where consumers pick up the next event in line. Kafka will only cache and store messages for a specific amount of time, and then they are deleted. If a consumer does not retrieve the next event in time, a growing organization without scaled resources could experience deleted important events.
Administrators responsible for Kafka performance need to update and maintain servers continually. As events increase, partitions and consumer resources also must increase. A spike in logged events could cause a bottleneck in the Kafka system, where events are deleted and lost without administrator knowledge. Should a significant event happen, such as a cybersecurity event, administrators might be unaware of a compromise and data breach.
How Can Logging Bottlenecks be Avoided?
Although Kafka can be sufficient in smaller environments, large enterprises need a more robust and scalable solution to handle increases in events. We engineered Mezmo, formerly LogDNA, to handle millions of log lines per second and over 20 terabytes of data a day. We originally tested our solution with Elasticsearch and the many variables that go with enterprise logging and events. The logging solutions from Mezmo can seamlessly pick up where Kafka scaling drops off.
Table of Contents
Share Article


RSS Feed





.png)


.jpg)








.png)























.png)