
It is 12PM and you just start eating lunch when your phone starts buzzing. A storm of different monitoring and system-level alerts start stacking up on your phone and slack. The incident response "war room" opens and downtime communications are being drafted to customers. Your team is under pressure to find the root cause, but you are immediately hit with roadblocks. You try to make sense of the noise, by sifting through volumes of logs in Dynatrace, only to wait minutes--or hours--for critical diagnostic data to be rehydrated from a cold storage archive like S3.
During an incident, nothing is more important than timely access to accurate information. Engineers don't need more data; they need the right data that provides a clear, targeted view into what’s going wrong. Every second spent searching for context or waiting for a data pipeline is a second added to your Mean Time to Resolution (MTTR).
This leads directly to the "cost vs. context" paradox. As we discussed in our last post, controlling costs often means filtering out verbose, high-volume data. But during an incident, that filtered data might contain the one clue needed to solve the problem. How can you have both aggressive cost savings and complete visibility when it matters most?
The Solution: The Risk-Free Way to Troubleshoot
Mezmo solves this paradox by giving you on-demand access to full-fidelity raw data, precisely when you need it, without the cost of storing it all long-term.
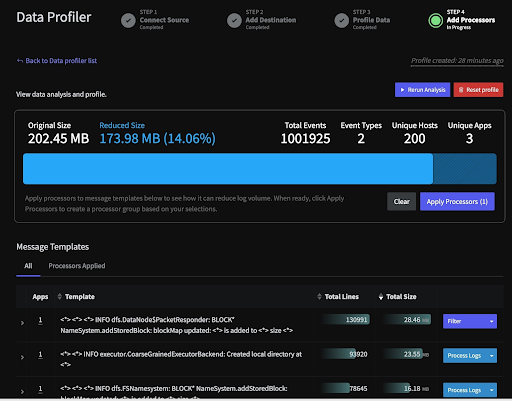
Automatically Generate a Cheat Sheet with Data Profiler
Developers that are on-call need to understand issues fast. Data Profiler can show you where the smoking gun is while reducing any noise not directly tied to the root cause issue. It can even be triggered automatically, as soon as the issue is detected, so the information is ready as soon as you are.
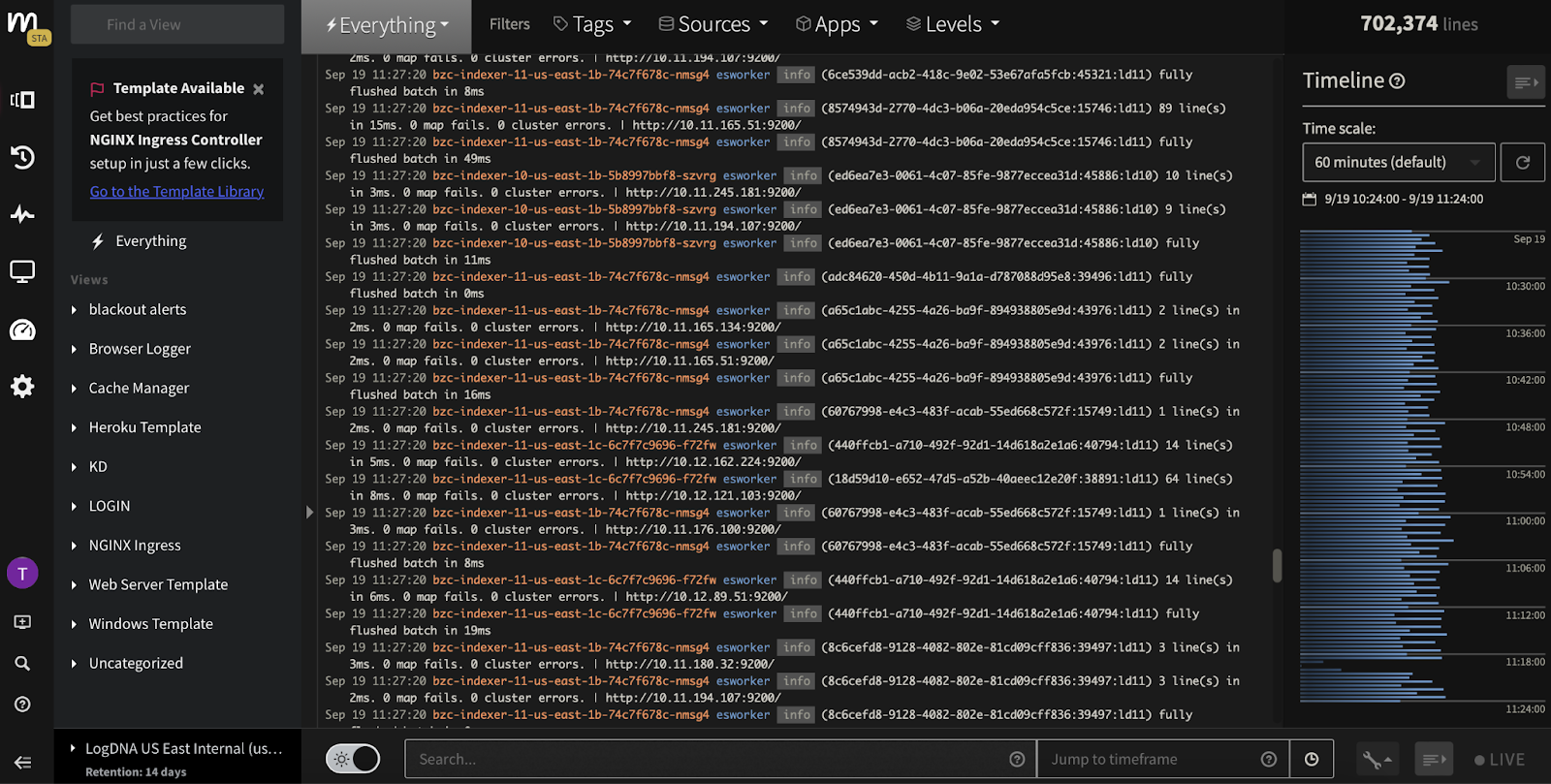
Find the Signal in Real-Time with Live Tail
During a high-stakes incident, you can't afford to wait for data to be indexed by Dynatrace. Mezmo's Live Tail lets your engineers view the raw log and event stream in real-time, before it hits any platform. This allows them to see what’s happening at the exact moment it occurs, finding the root cause in seconds, not minutes.
Accelerate Analysis with MCP
For developers who need real-time analysis, the Mezmo Context Provider (MCP) offers another powerful path to answers. Our hosted MCP server provides a direct endpoint for your AI tools, letting you run advanced root-cause analysis on recent logs using natural language, all without leaving your workspace, while also serving as the engine for our upcoming automated incident response features.
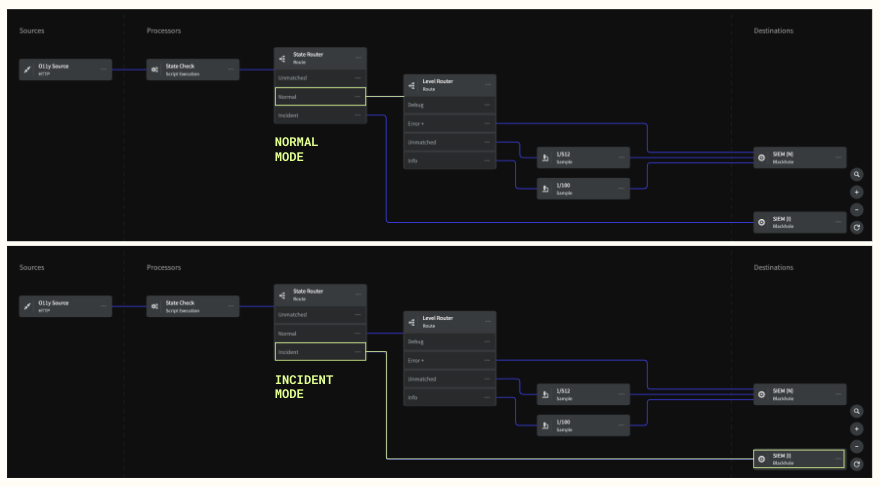
The Ultimate Safety Net: Responsive Pipelines & Replay
This is where Mezmo’s architecture becomes a game-changer. Even while you're filtering, aggregating, and sampling data to control costs, Mezmo's Responsive Pipelines automatically keep a short-term, full-fidelity replay buffer of all your raw data (e.g., the last 8 hours). When an incident is detected—perhaps by a Dynatrace alert—you can instantly "replay" that raw, high-context data directly into Dynatrace for deep analysis. No rehydration delays. No frantic searching. You get 100% of the context, on-demand, without paying to store it 24/7. This makes aggressive filtering and sampling completely risk-free.
Guarantee Capture of Error Traces
With Tail-Based Sampling, you can be confident that you’re eliminating noise, not critical signals. Mezmo guarantees 100% capture of important traces containing errors or high latency, ensuring your engineers always have the context they need to troubleshoot the most difficult problems.
Better Together: An Automated Incident Workflow
Imagine this workflow:
- Dynatrace's Davis AI detects an anomaly and fires an alert.
- A webhook from Dynatrace automatically triggers Mezmo's Responsive Pipeline to switch into "incident mode."
- Mezmo instantly replays the full-fidelity data from the minutes surrounding the alert directly into Dynatrace.
- Your engineers arrive at the incident with the exact, high-context data they need, ready for analysis.
This powerful integration means your team isn't digging for data; they're diagnosing the problem.
Conclusion
Stop letting data latency and availability slow down your incident response. By combining Mezmo's real-time troubleshooting and on-demand replay capabilities with Dynatrace's powerful analytics, you can dramatically reduce your MTTR, eliminate context-switching for your engineers, and diagnose and fix problems faster. And most importantly, eliminate those darn lunch disruptions so you can enjoy that sandwich.
Start your 30-day free trial of Mezmo here.
More blog posts



