LogDNA vs. Papertrail
LogDNA is now Mezmo but the insights you know and love are here to stay.

What Does Papertrail Do?
Papertrail is a log management company that allows users to aggregate, organize, and manage their logs. Features include live tail, search, parsing, views, and alerts.
In 2015, Papertrail was acquired by Solarwinds, an American company that develops software to manage networks, systems, and IT infrastructure (you’ve probably heard of them). This makes Papertrail part of the SolarWinds for DevOps family of products which also includes Loggly, AppMetrics, and Pingdom.
Papertrail Limitations and Disadvantages
If you’re looking for more robust features and customizations, Papertrail may not be the solution for you. Papertrail automatically parses logs, but it doesn’t support custom parsing, which is essential for proprietary formats. The search function can be slow and when you do find the log line you’re looking for, you can’t expand it to see the raw log. Although it has all the right alert integrations, alerts are managed manually, they’re frequency-based, and they automatically turn off at a certain threshold. And, since Papertrail has limited analysis features, users have to export logs to another platform to identify trends and anomalies.
Lastly, Papertrail is on the pricier side compared to other log management solutions with the same or more robust functionality. Self service pricing ranges based on ingestion volume, from 1-1500 GBs, and retention period, from one day to four weeks. Every plan has a hard cap and if you surpass it, you pay your initial rate plus a 30% increase. All plans do include one year of archiving and unlimited noise filtering, which is helpful.
Benefits of Using LogDNA
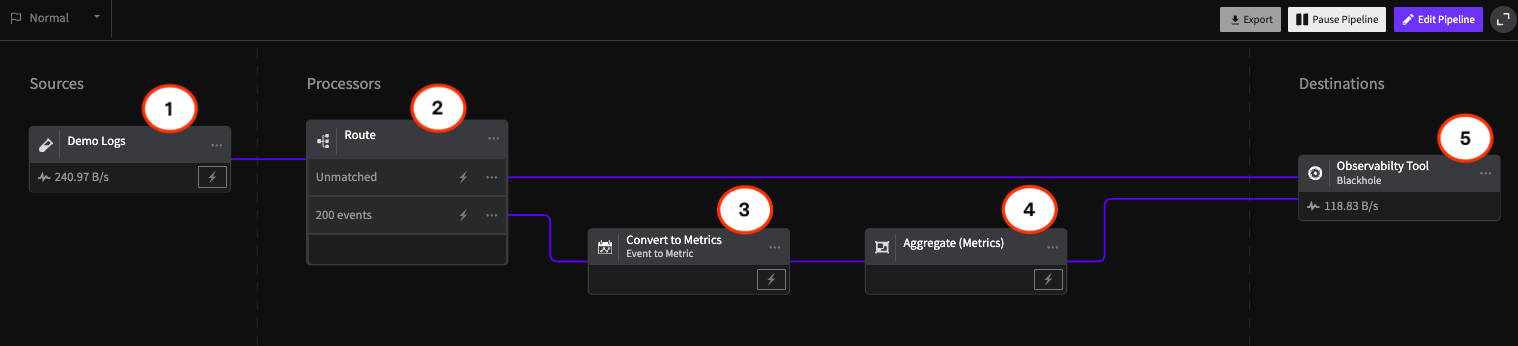
LogDNA was built to ingest, process, and analyze log data at hyperscale. Our proprietary messaging bus intelligently detects log types, automatically parses them, and indexes them in a way that makes keyword search fast and easy to use. For non-standard log types, you can easily configure Custom Parsing rules. You can save Views for a shortcut to a specific set of filters and search queries, visualize your logs using Boards, Graphs, and Screens, and receive real-time Alerts in PagerDuty, Slack, email, or via a custom Webhook.
Being able to get maximum value from your log data is only one part of the equation. You also have to be able to control costs and scale up and down as needed, without caps on usage. LogDNA offers multiple control features to self service customers including Exclusion Rules, which allow you to filter out logs by sources, by apps, or by specific queries that you want to see in Live Tail and be alerted on, but that you don’t want to store. Since we charge based on retention, these logs won’t count towards your bill. You can also automatically archive logs to Amazon S3, IBM Cloud Object Storage, Google Cloud Storage, Azure Blob Storage, and more.
For enterprise customers who need advanced control features, LogDNA launched the Spike Protection Bundle, which includes Index Rate Alerting and Usage Quotas. When there’s an unexpected spike in ingestion, Index Rate Alerting provides actionable insight into which applications, sources, or tags produced the data spike, as well as any recently added sources. Usage Quotas let you specify soft and hard thresholds for the volume of log files to store. When the threshold is met, LogDNA will notify you and apply your defined configurations.
Earlier this month, we announced our early access program for Variable Retention, which gives you the flexibility to save logs in LogDNA only for the amount of time that they're relevant. This makes it possible to ingest new types of log data while keeping cost under control, allowing teams to leverage their logs for even more use cases. Our engineering team has even more control features on the product roadmap that will become available over the course of the next year.
Table of Contents
Share Article


RSS Feed






.png)


.jpg)








.png)























.png)