
Synthetic tracing can be an alternative for modern observability teams, helping them avoid the cost of tracing every click. Better data, lower bills — what’s not to like?
In modern observability practices, distributed tracing has become table stakes. Most application performance monitoring (APM) platforms encourage an “instrument everything” approach: Deploy an SDK or agent, hook into every service call and capture every user interaction at scale. On paper, this sounds like complete visibility. In practice, it can turn into a costly firehose of data with diminishing returns. To put this in perspective: If you have a 0.1% failure rate, you’re still capturing 99.99% of tracing and logging data you will most likely never use.
Honeycomb makes a compelling argument: “Every new host, pod, node or service adds to the APM bill… As they consume custom metrics, index data in additional formats such as traces and logs, and ration seat access, buyers are faced with a cost-visibility trade-off. Teams either find themselves overpaying for observability or sacrificing visibility to control costs.”
Enter synthetic tracing, a targeted, proactive approach that flips the model on its head. Instead of tracing every real user request, synthetic tracing executes controlled, continuous test transactions that mirror real user journeys. These synthetic transactions can be traced end to end across your distributed stack. The result: reduced costs, cleaner data and faster detection of meaningful issues.
Let’s break down why synthetic tracing is worth serious consideration, especially as observability costs and data sprawl continue to spiral.
What Is Synthetic Tracing in APM?
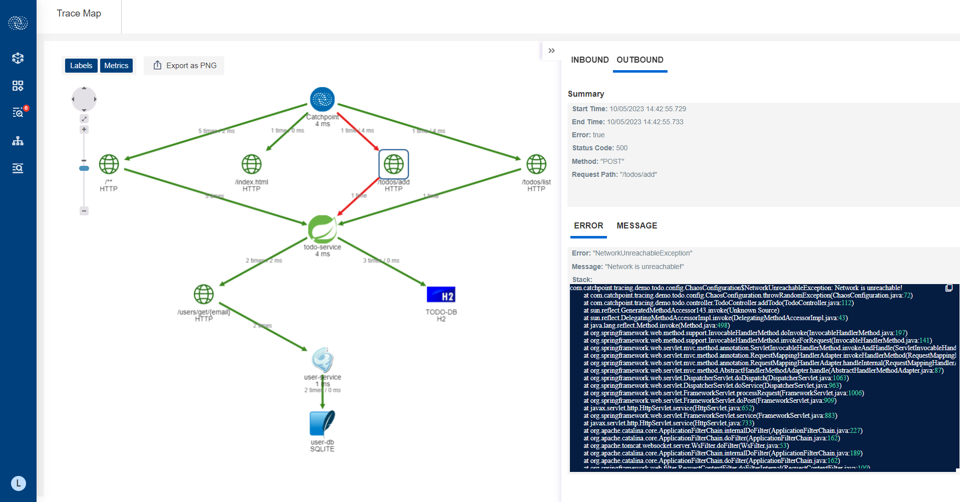
Synthetic tracing is the practice of generating controlled, scripted transactions against your application and then instrumenting those test interactions with distributed tracing. It’s like sending a robot to test your app before real people use it. This robot follows a set of steps, such as logging in and making a payment, to verify that everything works as expected. Instead of waiting for real users to trigger a span or transaction, synthetic requests enable you to catch problems early, much like a canary used to warn miners about dangerous air.
For example, you might configure a synthetic trace to:
- Log into an application with a test account.
- Perform a series of API calls (search, checkout, payment) that represent a critical user flow.
- Capture spans across services, databases, caches and external dependencies as the synthetic request propagates.
How Synthetic Tracing Differs From Real User Tracing
The key difference from real-user tracing is control:
- Consistency: The same transaction is executed repeatedly at the interval you define, from the same location, even when users are not active. With traditional distributed tracing, data is often polluted by a high percentage of bots, which add noise and potentially mask real issues.
- Predictability: Because the test inputs are fixed, any variability in the trace output highlights a genuine system change or degradation.
- Completeness: Each synthetic request is guaranteed to traverse the entire internet stack as scripted, giving you an end-to-end trace of that journey every time.

For site reliability engineering (SRE)/DevOps teams, this means you can baseline performance for critical workflows, pinpoint bottlenecks and proactively validate fixes without waiting for a user to stumble across a problem first. If needed, you can always add tools like OpenTelemetry to capture all errors, including those of real users and or samples.
The ‘Trace Everything’ Approach: Useful, But Expensive
Traditional APM tracing relies on SDKs or agents to capture every request flowing through your application. Every API call, every database query, every interservice hop is captured and shipped off for aggregation. As Mezmo states “Most teams capture everything all the time, leading to expensive, overwhelming and often unnecessary data volumes.” While this provides massive amounts of data, it also creates several challenges:
- Cost explosion: More data means higher storage and processing costs. Many teams end up with surprise overages as trace and log volumes exceed projections.
- Noise vs. signal: With every request captured, meaningful anomalies can be buried in a mountain of otherwise healthy transactions.
- Alerting thresholds: To avoid drowning in alerts, APMs typically require failure thresholds ( X% of requests failing) before triggering an incident. That means an issue is already affecting multiple users before you even know it exists.
- Reactive posture: You’re always waiting for a real user to stumble into a problem before it shows up in your traces.
The investment might be acceptable for some for Tier-1 apps where every transaction is mission critical or for new releases in QA cycles, but for Tier-2 and Tier-3 apps, the ROI becomes questionable. Worse, the “more data is better” philosophy often backfires by overwhelming both budgets and teams.
TRENDING STORIES
- OpenTelemetry Adoption Update: Rust, Prometheus and Other Speed Bumps
- Observability Is Stuck in the Past. Your Users Aren’t
- Control Fluent Bit Backpressure With Prometheus
- Why Synthetic Tracing Delivers Better Data, Not Just More Data
- When To Use Synthetic Monitoring vs. Real User Monitoring
Further, the amount of data creates an illusion that the answer must be somewhere in the haystack of logs, events and traces. However, blind spots still exist: A significant portion of the stack in today’s distributed, service-dependent applications remains untraceable. To mitigate this, often the approach is to firehose logs from those services, but often that’s not enough because when those services are down or misbehaving; there is nothing useful in the logs they provide.
Synthetic Tracing: Controlled, Continuous, Cost-Efficient
Synthetic tracing takes a different path. Instead of capturing all user interactions, you control when and how tracing occurs:
- Configurable frequency: You decide how often synthetic transactions run (every minute, every five minutes, etc.). The cadence balances visibility with cost and is completely predictable and under control from a cost perspective.
- Immediate alerts: Since every synthetic run is a controlled test, any failure or degradation can trigger an alert immediately. There’s no need to hit a threshold of failed real-user interactions. If in doubt, an instant test can be called to confirm the failure in seconds.
- Proactive monitoring: Synthetic tests run continuously, even when no users are active. That means you can detect outages or regressions during off hours before customers encounter them. It also means you can proactively test edge cases and user journeys that are less common but still important. There’s no need to wait for users to encounter a problem.
- Cleaner data: Every trace corresponds to a known test case, eliminating noise. Troubleshooting becomes simpler because you know exactly what was tested, when and under what conditions.
- Real-world context: Because synthetic tracing is part of internet performance monitoring (IPM), tests can be run from thousands of global vantage points: last mile, wireless, backbone and cloud locations that mirror the real-world conditions of users. It also provides visibility into not only your application’s backend, but also the real-world performance context: DNS, networks, CDNs, ISPs, WANs, cloud services, third-party dependencies, APIs and everything in between.
- Enterprise agents: You have the flexibility to deploy agents within your infrastructure that can operate freely behind your firewall and can monitor with increased frequency at a very low cost.
Why This Matters for Tiered Applications
For Tier-1 business-critical systems, full distributed tracing may remain a non-negotiable requirement. But many organizations are discovering that synthetic tracing is more than sufficient for Tier-2 and Tier-3 apps, where:
- The business impact of an individual transaction is lower.
- The volume of requests makes tracing everything prohibitively expensive.
- The need is primarily proactive assurance rather than forensic replay of every user journey.
Over time, even Tier-1 applications can benefit from a hybrid approach: Use synthetic tracing to continuously validate baseline performance and availability, while keeping full APM tracing for high-value transactions or complex incident investigations.
For some organizations, synthetic tracing may be the right approach. Especially when considering the cost of operations for a software company, where 10% of cost of goods sold (COGS) is allocated to infrastructure and 5% to personnel, while spending 5% on monitoring may be unacceptable. Monitoring shouldn’t be more than 1% to 2 % of the revenue of a product; otherwise, the company will struggle to make the operating margins work.
Why Better Data is More Important Than More Data
The industry mantra has long been “more data equals more visibility.” Synthetic tracing challenges that assumption. In reality, better data is better.
Targeted traces capture the right context at the right time. Controlled test conditions eliminate variability and guesswork, and, of critical importance, global vantage points ensure you understand not just what the server executed, but how it felt to an end user in São Paulo, Singapore or San Francisco.
Monitoring exclusively from hyperscaler environments misses essential real-world variables like last-mile congestion, ISP routing, carrier-grade NAT, local DNS resolution and edge/cache viability. These are not theoretical gaps; they have a material impact on how users experience applications every day.
This precision means teams spend less time sifting through noisy trace data and more time solving real problems.
Synthetic tracing won’t replace APM everywhere, nor should it. But for organizations struggling with observability costs and alert fatigue, it offers a powerful complement — and in many cases, a smarter, more sustainable path forward.
Sometimes less really is more. Or rather: Better is better.
More news



